組み合わせ編
LAMBDA 関数を使った数式によるユーザー定義関数(カスタム関数)として、実用的かつコピペで使えるサンプルコードをまとめていきたいと思います。
使い方は以下の記事を参照してください。
本記事ではデータの組み合わせに関連する各種の関数を集めてみました。
また、もっと他にも、あったら便利なデータの組み合わせ方があれば、教えてください。
【使用上の注意】
- 本記事に掲載している数式は LAMBDA 関数をサポートしてる Excel(現状、 Microsoft 365 版(サブスク版)Excel のみ)で使用可能です。
- 本ブログに記載のLAMBDA 数式は全て単独で利用できます。必要な関数のみを「名前の定義」で「参照範囲」にコピー&ペーストしてください。
- 関数名となる「名前」は一例を示していますが、任意の名前をつけて問題ありません。
- 不具合、使い勝手の改善、欲しい機能等ご意見ご希望がありましたら、本記事のコメントか Twitter にてお知らせください。
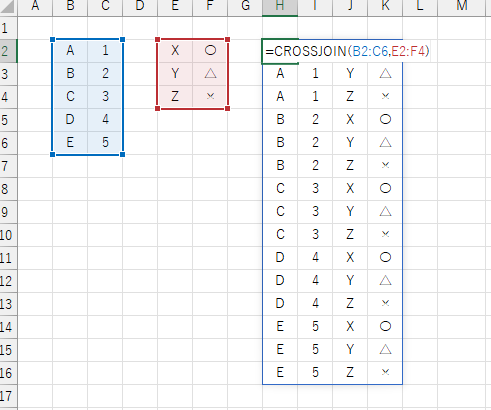
2つのリストからの行の組み合わせ
【名前の定義】
名前
CROSSJOIN
コメント
2つのリストの直積を生成します
参照範囲
=LAMBDA(リスト1, リスト2,
LET(
lhz, ROWS(リスト1),
rhz, ROWS(リスト2),
seq, SEQUENCE(lhz * rhz),
lhrs, CEILING.MATH(seq / rhz),
rhrs, MOD(seq - 1, rhz) + 1,
lhcs, SEQUENCE(, COLUMNS(リスト1)),
rhcs, SEQUENCE(, COLUMNS(リスト2)),
HSTACK(INDEX(リスト1, lhrs, lhcs), INDEX(リスト2, rhrs, rhcs))
)
)
【構文】
CROSSJOIN(リスト1, リスト2)
【引数】
| 引数 | 内容 |
|---|---|
| リスト1 | データのセル範囲または配列 |
| リスト2 | データのセル範囲または配列 |
【戻り値】
行の組み合わせのパターンからなる配列。
【説明】
CROSSJOIN は与えられた2つのリストの各行について組み合わせた、全てのパターンを配列で返します。結果は縦方向にスピルします。
リスト1, リスト2 には、組み合わせたいデータを持つリストをセル範囲または配列で指定します。 各リスト が複数列からなるデータであれば、行単位の組み合わせとなります。
【使用例】
以下は「商品名」、「サイズ」、「色」の組み合わせを作成した例です。 CROSSJOIN 関数を入れ子にして、3つのリストの全ての組み合わせを生成しています。 リスト範囲の指定には Excel テーブル名(構造化参照)を使用しています。
=CROSSJOIN(CROSSJOIN(商品マスタ[商品名], サイズマスタ), 色マスタ)

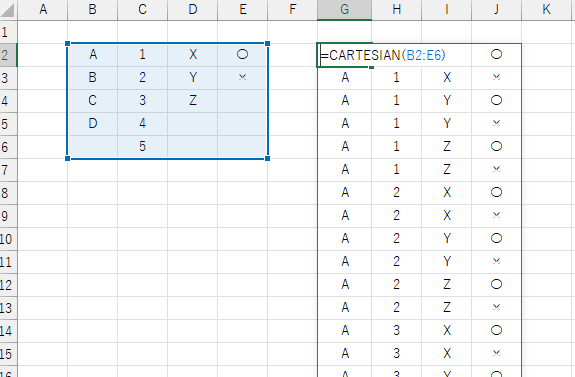
複数集合の要素の組み合わせ
【名前の定義】
名前
CARTESIAN
コメント
各列の値から直積を生成します
参照範囲
=LAMBDA(複数列データ,
LET(
_selfy, LAMBDA(f, LAMBDA(x, f(f, x))),
_crossjoin, LAMBDA(lhs, rhs,
LET(
lhz, ROWS(lhs),
rhz, ROWS(rhs),
seq, SEQUENCE(lhz * rhz),
lhrs, CEILING.MATH(seq / rhz),
rhrs, MOD(seq - 1, rhz) + 1,
lhcs, SEQUENCE(, COLUMNS(lhs)),
rhcs, SEQUENCE(, COLUMNS(rhs)),
HSTACK(INDEX(lhs, lhrs, lhcs), INDEX(rhs, rhrs, rhcs))
)
),
_values, LAMBDA(arr, FILTER(arr, arr <> "", #VALUE!)),
_cartesian, _selfy(
LAMBDA(self, arr,
IF(
COLUMNS(arr) = 1,
_values(arr),
LET(
lhs, _values(TAKE(arr, , 1)),
rhs, self(self, DROP(arr, , 1)),
crossjoin(lhs, rhs)
)
)
)
),
_cartesian(複数列データ)
)
)
【構文】
CARTESIAN(複数列データ)
【引数】
| 引数 | 内容 |
|---|---|
| 複数列データ | セル範囲または配列 |
【戻り値】
各列の値どうしの全ての組み合わせパターンからなる配列。
【説明】
CARTESIAN は、与えられたセル範囲か配列の各列ごとの値を集合とみなし、全ての集合間の値の組み合わせパターンを生成します。 結果は配列で、縦方向にスピルします。
「複数列データ」には、組み合わせたい集合を1列1集合として一つのセル範囲か配列にまとめて指定します。
空値や空文字列は無視されますので、各集合列の要素数がバラバラで隙間だらけになっても問題ありません。
値が一つもない列(空列)が含まれるとエラーになります。
先ほどの CROSSJOIN と似ていますが、以下のような使い勝手の違いがあります。対象となるデータに合わせて使い分けてください。
- CROSSJOIN 関数
- 指定できるデータリストは2つまで
- 各リストは複数列からなるセル範囲や配列を指定でき、行(レコード)ごとの組み合わせを作れる
- CARTESIAN 関数
- データ列の列数により任意の数の集合を組み合わせることができる
- 1列1集合なので、値同士の組み合わせしかできない
【使用例】
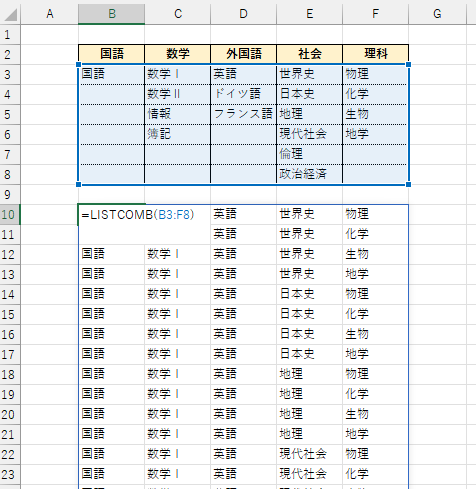
以下は入試での選択科目のありうる組み合わせを全て洗い出しています。
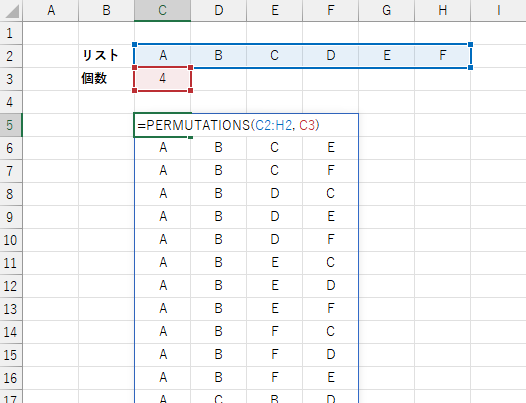
n 個の要素から k 個を並べる組み合わせ(順列)
【名前の定義】
名前
PERMUTATIONS
コメント
要素集合から選択個数を並べた順列を生成します
参照範囲
=LAMBDA(要素集合, [選択個数],
LET(
_selfy2, LAMBDA(f, LAMBDA(x, y, f(f, x, y))),
_vStackMap, LAMBDA(xs, f, DROP(REDUCE(0, xs, LAMBDA(acc, x, VSTACK(acc, f(x)))), 1)),
_vArray, LAMBDA(n, init, EXPAND(init, n, 1, init)),
_permutations, _selfy2(
LAMBDA(self, vals, k,
IF(
k = 1,
vals,
_vStackMap(
vals,
LAMBDA(curr,
LET(
rest, FILTER(vals, vals <> curr),
succs, self(self, rest, k - 1),
prec, _vArray(ROWS(succs), curr),
HSTACK(prec, succs)
)
)
)
)
)
),
set, TOCOL(要素集合),
vals, FILTER(set, set <> ""),
n, ROWS(vals),
k, IF(ISOMITTED(選択個数), n, 選択個数),
IFS(
NOT(ISNUMBER(k)),
"#選択個数が整数ではありません",
k <> INT(k),
"#選択個数が整数ではありません",
OR(k < 1, n < k),
"#選択個数が範囲外です",
TRUE,
LET(
perms, _permutations(SEQUENCE(n), k),
INDEX(vals, perms, 1)
)
)
)
)
【構文】
PERMUTATIONS(要素集合, [選択個数])
【引数】
| 引数 | 内容 |
|---|---|
| 要素集合 | 要素を含むセル範囲または配列 |
| 選択個数 | 取り出す要素の個数、省略すると全要素 |
【戻り値】
全ての順列パターンを網羅した配列。
【説明】
PERMUTATIONS は指定の値の組からある個数を選んだ並び(順列組み合わせ)の、ありうる組み合わせパターンを全て生成します。 結果は、1 行に 1 パターン で nPk 行の配列となり、スピルします。
「要素集合」には値の組をセル範囲か配列で指定します。 配列の形は任意で、空白や空文字列は除外されます。
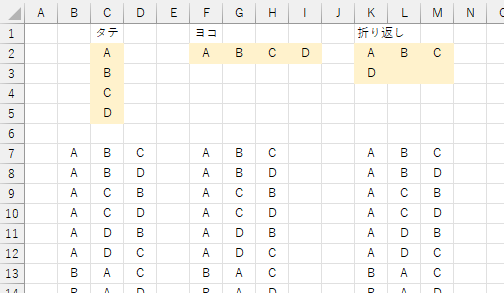
「選択個数」は選び出す要素の個数を指定します。 省略すると、全要素の個数となります。
2 番目のパラメータを省略 =PERMUTATIONS(A1:A5)
【注意】 要素数を増やしすぎると場合の数が爆発的に増え、すぐに Excel がフリーズしてしまいます。 場合の数(nPk)が多くても 100 万を超えないよう、あらかじめ注意してください。 場合の数を見積もるには PERMUT 関数 が使えます。
【使用例】
ある営業マンが、担当地域にある複数の店舗を全て巡回するとき、どの順番で回ると交通費を一番抑えられるかを知りたいとします。
その経路の洗い出しには、店舗の順列データが必要です。
以下は、A、B、C、D、E という 5 店舗があり、A店から出発開始し、E店に最終到着するような経路の交通費を洗い出しています。
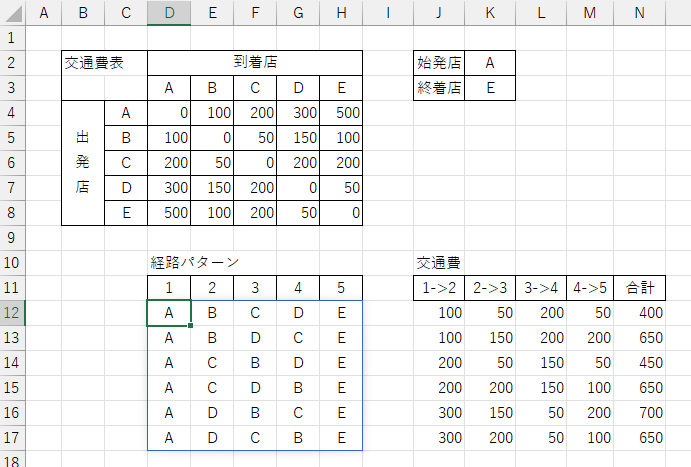
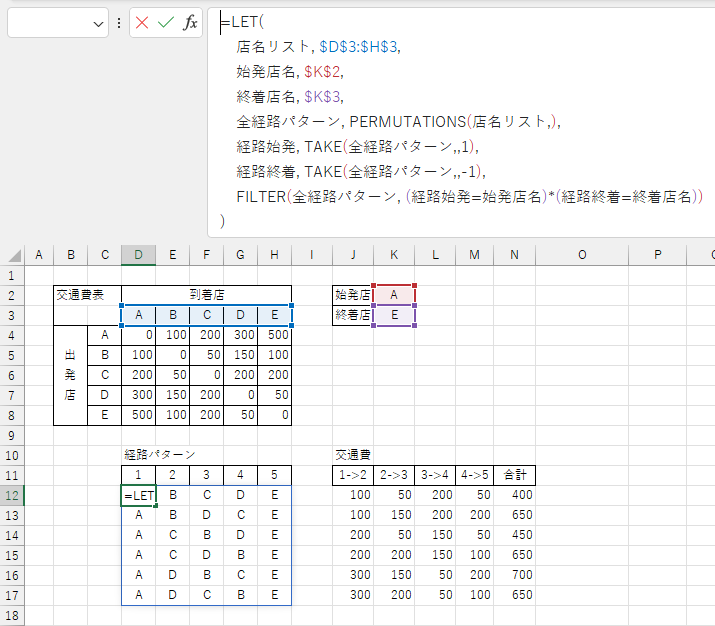
まず店名リストから PERMUTATIONS で全経路パターンを洗い出し、FILTER 関数を使って始発と終着で絞り込みます。
$D$12 セルには以下の数式が入力されています。
=LET(
店名リスト, $C$4:$C$8,
始発店名, $K$2,
終着店名, $K$3,
全経路パターン, PERMUTATIONS(店名リスト,),
経路始発, TAKE(全経路パターン,,1),
経路終着, TAKE(全経路パターン,,-1),
FILTER(全経路パターン, (経路始発=始発店名)*(経路終着=終着店名))
)
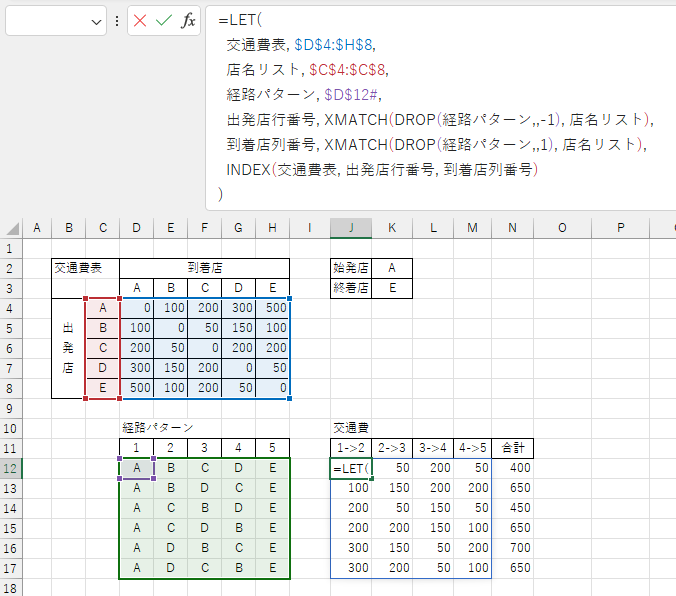
あとは交通費表から店舗間の交通費を引いてきて経路ごとに合計します。
$J$12 セルには以下の数式が入力されています。
=LET( 交通費表, $D$4:$H$8, 支店名リスト, $C$4:$C$8, 経路パターン, $D$12#, 出発行番号, MATCH(DROP(経路パターン,,-1), 支店名リスト), 到着列番号, MATCH(DROP(経路パターン,,1), 支店名リスト), INDEX(交通費表, 出発行番号, 到着列番号) )
n 個の要素から k 個を取り出す組み合わせ(組合せ)
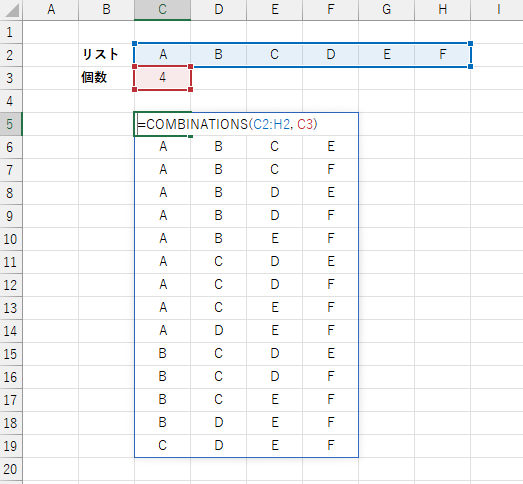
【名前の定義】
- 名前
COMBINATIONS
「COMBINATION」という名前だとエラーになります。Excel で予約されているようです。
コメント
要素集合から選択個数を順序を区別しない組み合わせを生成します
参照範囲
=LAMBDA(要素集合, [選択個数],
LET(
_selfy2, LAMBDA(f, LAMBDA(x, y, f(f, x, y))),
_vStackMap, LAMBDA(xs, f, DROP(REDUCE(0, xs, LAMBDA(acc, x, VSTACK(acc, f(x)))), 1)),
_vArray, LAMBDA(n, init, EXPAND(init, n, 1, init)),
_combinations, _selfy2(
LAMBDA(self, vals, k,
IF(
k = 1,
vals,
_vStackMap(
SEQUENCE(ROWS(vals) - k + 1),
LAMBDA(i,
LET(
curr, INDEX(vals, i, 1),
rest, DROP(vals, i),
succs, self(self, rest, k - 1),
prec, _vArray(ROWS(succs), curr),
HSTACK(prec, succs)
)
)
)
)
)
),
set, TOCOL(要素集合),
vals, FILTER(set, set <> ""),
n, ROWS(vals),
k, IF(ISOMITTED(選択個数), n, 選択個数),
IFS(
NOT(ISNUMBER(k)),
"#選択個数が整数ではありません",
k <> INT(k),
"#選択個数が整数ではありません",
OR(k < 1, n < k),
"#選択個数が範囲外です",
TRUE,
LET(
combs, _combinations(SEQUENCE(n), k),
INDEX(vals, combs, 1)
)
)
)
)
【構文】
COMBINATIONS(要素集合. [選択個数])
【引数】
| 引数 | 内容 |
|---|---|
| 要素集合 | 要素の値を含むセル範囲または配列 |
| 選択個数 | 取り出す要素の個数、省略すると全要素 |
【戻り値】
全ての組合せパターンを網羅した配列。
【説明】
COMBINATIONS は複数の値から任意の個数を取り出し、順序を区別しないときのありうる全ての組み合わせパターンを生成します。 結果は、1 行に 1 パターン で nCk 行の配列となり、スピルします。
「要素集合」には値の組をセル範囲か配列で指定します。 配列の形は任意で、空白や空文字列は除外されます。
「選択個数」は選び出す要素の個数を指定します。 省略すると、全要素の個数(すなわち1通り)となります。
2 番目のパラメータを省略 =COMBINATIONS(A1:A5)
【注意】 要素数を増やしすぎると場合の数が爆発的に増え、すぐに Excel がフリーズしてしまいます。 場合の数(nCk)が多くても 100 万を超えないよう、あらかじめ注意してください。 組合せの場合の数を見積もるには COMBIN 関数 が使えます。
【使用例】
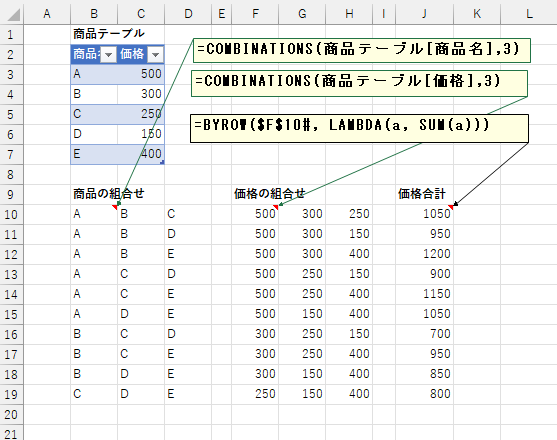
5 商品から 3 商品を選んだセット商品を作るのですが、その合計価格が 1000 円以下になる組み合わせのみにしたいとします。
合計価格の洗い出しには、商品の組合せデータが必要です。
以下の例では、商品テーブルから商品名の組合せと価格の組合せを COMBINATION で洗い出しています。 データの参照には Excel テーブル名による構造化参照を使っています。
AFE ソース
Excel に Advanced Formula Environment アドインを導入されている上級者のために、本記事掲載の全てのユーザー定義関数を一括登録できるソースを用意しました。
以下のソースを AFE の Editor にコピー&ペーストしてください。 関数名の衝突を避けるため、任意の名前で専用の Namespace を用意することをお勧めします。
// シーゴの Excel 研究室
// 【Excel LAMBDA】組み合わせ編【ユーザー定義関数集】
// https://www.shegolab.jp/entry/excel-lambda-combination-01
/**
* 2つのリストの組み合わせ
*/
CROSSJOIN = LAMBDA(リスト1, リスト2,
LET(
lhz, ROWS(リスト1),
rhz, ROWS(リスト2),
seq, SEQUENCE(lhz * rhz),
lhrs, CEILING.MATH(seq / rhz),
rhrs, MOD(seq - 1, rhz) + 1,
lhcs, SEQUENCE(, COLUMNS(リスト1)),
rhcs, SEQUENCE(, COLUMNS(リスト2)),
HSTACK(
INDEX(リスト1, lhrs, lhcs),
INDEX(リスト2, rhrs, rhcs)
)
)
);
/**
* 直積
*/
CARTESIAN = LAMBDA(複数列データ,
LET(
// 名前の定義なしで LAMBDA の再帰呼び出しを可能する仕掛け。
_selfy, LAMBDA(f, LAMBDA(x, f(f, x))),
// 2つのリストの各行の組み合わせを生成する関数
_crossjoin, LAMBDA(lhs, rhs, LET(
lhz, ROWS(lhs),
rhz, ROWS(rhs),
seq, SEQUENCE(lhz * rhz),
lhrs, CEILING.MATH(seq / rhz),
rhrs, MOD(seq - 1, rhz) + 1,
lhcs, SEQUENCE(, COLUMNS(lhs)),
rhcs, SEQUENCE(, COLUMNS(rhs)),
HSTACK(
INDEX(lhs, lhrs, lhcs),
INDEX(rhs, rhrs, rhcs)
)
)),
// 配列の空値を除去
_values, LAMBDA(arr, FILTER(arr, arr <> "", #VALUE!)),
// 列ごとの直積を生成する
_cartesian, _selfy(LAMBDA(self,
arr,
if(COLUMNS(arr) = 1,
_values(arr),
LET(
lhs, _values(TAKE(arr,, 1)),
rhs, self(self, DROP(arr,, 1)), // 再帰
_crossjoin(lhs, rhs)
)
)
)),
_cartesian(複数列データ)
)
);
/**
* 順列
*/
PERMUTATIONS = LAMBDA(要素集合, [選択個数],
LET(
// 名前の定義なしで LAMBDA の再帰呼び出しを可能する仕掛け。
// 引数を2個渡せる関数用。
_selfy2, LAMBDA(f, LAMBDA(x, y, f(f, x, y))),
// 配列要素に関数を適用した結果の配列をタテ方向に結合するというエセflatMap的な仕掛け。
_vStackMap, LAMBDA(xs, f, DROP(REDUCE(0, xs, LAMBDA(acc, x, VSTACK(acc, f(x)))), 1)),
// init 値で初期化された要素数 n のタテの配列を生成する。
_vArray, LAMBDA(n, init, EXPAND(init, n, 1, init)),
// 順列生成
_permutations, _selfy2(LAMBDA(self,
vals, // 要素集合
k, // 選択個数
IF(k = 1,
vals, // 選択個数に達していたら残りの要素を全て返す。
_vStackMap(vals, LAMBDA(
curr, // 各要素について・・・
LET(
rest, FILTER(vals, vals <> curr), // それ自体を除いた集合で・・・
succs, self(self, rest, k-1), // 子順列を再帰生成し・・・
prec, _vArray(ROWS(succs), curr), // それに自分の値を・・・
HSTACK(prec, succs) // 左端につける
)
))
)
)),
set, TOCOL(要素集合),
vals, FILTER(set, set<>""),
n, ROWS(vals),
k, IF(ISOMITTED(選択個数), n, 選択個数), // デフォルトで全要素数
IFS(
NOT(ISNUMBER(k)), "#選択個数が整数ではありません",
k <> INT(k), "#選択個数が整数ではありません",
OR(k < 1, n < k), "#選択個数が範囲外です",
TRUE, LET(
// 順列を生成。
// 処理時間短縮のため、要素そのものではなくそのインデックス(位置番号)を使う。
perms, _permutations(SEQUENCE(n), k),
// 実際の値に変換する。
INDEX(vals, perms, 1)
)
)
)
);
/**
* 組合せ
*/
COMBINATIONS = LAMBDA(要素集合, [選択個数],
LET(
// 名前の定義なしで LAMBDA の再帰呼び出しを可能する仕掛け。
// 引数を2個渡せる関数用。
_selfy2, LAMBDA(f, LAMBDA(x, y, f(f, x, y))),
// 配列要素に関数を適用した結果の配列をタテ方向に結合するというエセflatMap的な仕掛け。
_vStackMap, LAMBDA(xs, f, DROP(REDUCE(0, xs, LAMBDA(acc, x, VSTACK(acc, f(x)))), 1)),
// init 値で初期化された要素数 n のタテの配列を生成する。
_vArray, LAMBDA(n, init, EXPAND(init, n, 1, init)),
// 組合せ生成
_combinations, _selfy2(LAMBDA(self,
vals, // 要素集合
k, // 選択個数
IF(k = 1,
vals,
_vStackMap(SEQUENCE(ROWS(vals) - k + 1), LAMBDA(
i, // 各位置について・・・
LET(
curr, INDEX(vals, i, 1), // 値を取り出し・・・
rest, DROP(vals, i), // それ以降の集合で・・・
succs, self(self, rest, k-1), // 子組み合わせを再帰生成し・・・
prec, _vArray(ROWS(succs), curr), // それに自分の値を・・・
HSTACK(prec, succs) // 左端につける
)
))
)
)),
set, TOCOL(要素集合),
vals, FILTER(set, set<>""),
n, ROWS(vals),
k, IF(ISOMITTED(選択個数), n, 選択個数), // デフォルトで全要素数
IFS(
NOT(ISNUMBER(k)), "#選択個数が整数ではありません",
k <> INT(k), "#選択個数が整数ではありません",
OR(k < 1, n < k), "#選択個数が範囲外です",
TRUE, LET(
// 順列を生成。
// 処理時間短縮のため、要素そのものではなくそのインデックス(位置番号)を使う。
combs, _combinations(SEQUENCE(n), k),
// 実際の値に変換する。
INDEX(vals, combs, 1)
)
)
)
);
// EOF
関連記事
編集履歴
- [2022/09/25] 公開
- [2022/10/30] 一部文言の間違いを修正、PERMUTATIONS と COMBINATIONS の第2引数をオプショナルに修正。