データ分析編
LAMBDA 関数を使った数式によるユーザー定義関数(カスタム関数)として、実用的かつコピペで使えるサンプルコードをまとめていきたいと思います。
使い方は以下の記事を参照してください。
本記事では基本的なデータ分析に使えそうな関数を主に集めました。
データ分析の専門家ではないので、間違いや考慮漏れがあるかもしれません。 その場合は本記事のコメントか Twitter にてお知らせいただければ。
またほかにもあると便利なデータ分析があったら教えてください。
【使用上の注意】
- 本記事に掲載している数式は LAMBDA 関数をサポートしてる Excel(現状、 Microsoft 365 版(サブスク版)Excel のみ)で使用可能です。
- 本ブログに記載のLAMBDA 数式は全て単独で利用できます。必要な関数のみを「名前の定義」で「参照範囲」にコピー&ペーストしてください。
- 関数名となる「名前」は一例を示していますが、任意の名前をつけて問題ありません。
- 不具合、使い勝手の改善、欲しい機能等ご意見ご希望がありましたら、本記事のコメントか Twitter にてお知らせください。
基本統計量
【名前の定義】
- 名前
SUMMARY
- コメント
データから基本統計量を算出します
- 参照範囲
=LAMBDA([データ列], [カテゴリ列],
LET(
_visible_rows, LAMBDA(a,
IF(ISREF(a),
FILTER(a, BYROW(a, LAMBDA(r, AGGREGATE(3,3,r)>0))),
a
)
),
LET(
measureNames, {
"個数",
"合計",
"平均",
"中央値",
"最頻値",
"最小値",
"最大値",
"分散",
"標準偏差",
"尖度",
"歪度"
},
measureFuncs, LAMBDA(i, a,
CHOOSE(i,
COUNT(a),
SUM(a),
AVERAGE(a),
MEDIAN(a),
MODE.SNGL(a),
MIN(a),
MAX(a),
VAR.P(a),
STDEV.P(a),
KURT(a),
SKEW(a)
)
),
IF(ISOMITTED(データ列),
IF(ISOMITTED(カテゴリ列),
measureNames,
UNIQUE(_visible_rows(カテゴリ列))
),
IF(ISOMITTED(カテゴリ列),
LET(
vals, _visible_rows(データ列),
MAKEARRAY(1, COLUMNS(measureNames),
LAMBDA(r, c, measureFuncs(c, vals))
)
),
LET(
vals, _visible_rows(データ列),
categories, _visible_rows(カテゴリ列),
groups, UNIQUE(categories),
gids, XMATCH(categories, groups, 0, 1),
MAKEARRAY(ROWS(groups), COLUMNS(measureNames),
LAMBDA(gid, m, measureFuncs(m, FILTER(vals, gid=gids))))
)
)
)
)
)
)
【構文】
SUMMARY([データ列],[カテゴリ列])
【引数】
| 引数 | 内容 |
|---|---|
| データ列 | データのセル範囲または配列 |
| カテゴリ列 | グループ化するカテゴリデータのセル範囲または配列 |
【戻り値】
以下の統計量
| 統計量 | 対応関数 |
|---|---|
| 個数 | COUNT 関数 |
| 合計 | SUM 関数 |
| 平均 | AVERAGE 関数 |
| 中央値 | MEDIAN 関数 |
| 最頻値 | MODE.SNGL 関数 |
| 最小値 | MIN 関数 |
| 最大値 | MAX 関数 |
| 分散 | VAR.P 関数 |
| 標準偏差 | STDEV.P 関数 |
| 尖度 | KURT 関数 |
| 歪度 | SKEW 関数 |
【説明】
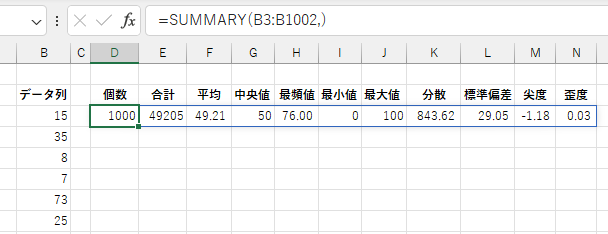
SUMMARY 関数は、指定したデータ列を母集団としたときの各基本統計量の一覧を、配列として返します。結果は横方向にスピルします。
「データ列」にはデータをセル範囲か配列として指定します。 対象データは1列目のみで、2列目以降は無視されます。
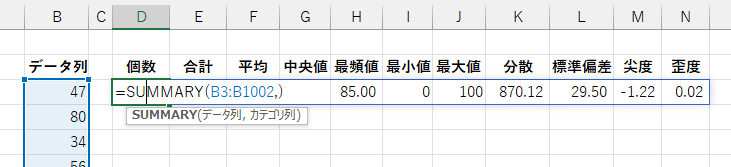
「データ列」に数値以外の値(空欄(空白セル)、文字列、論理値)があっても、計算上からは無視されます。
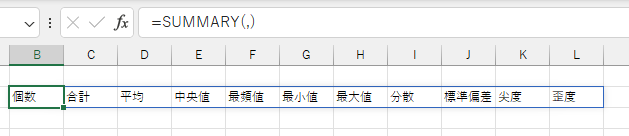
「データ列」が省略されると、各基本統計量の名称を配列として返します。 これを一覧表の見出し行として使用してください。
SUMMARY 関数は、カテゴリ別にグルーピングした集計を出すこともできます。
その場合、「カテゴリ列」にカテゴリ区分となるデータの列を指定します。
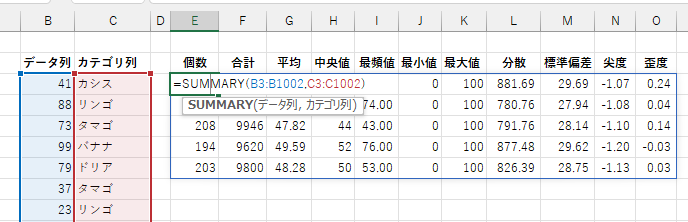
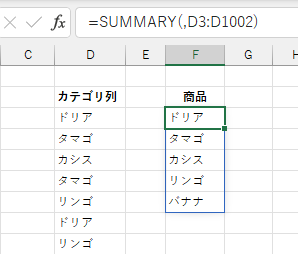
ただし、このままでは出力されるのが統計量のみで、カテゴリが分かりません。
カテゴリ名も表示するには、「データ列」を省略したうえで、「カテゴリ列」のみを指定します。
基本統計量表を完成させるにはこれらを組み合わせることになります。
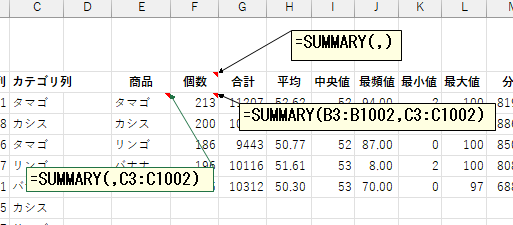
さらに、SUMMARY 関数では、非表示となっている行が計算から除外されるようになっています。
たとえば一部のデータのみを対象に集計したいときに、フィルターやグループ化で絞り込めれば、その範囲からのみの統計量が求まります。
また、異常値を除外したいときにも、データ元でその行を個別に非表示にすることで対応が可能です。
【使用例】
Excel テーブルから構造化参照による列指定で基礎統計量を求める。
=SUMMARY(売上テーブル[売上金額], 売上テーブル[顧客名])
偏差値
【名前の定義】
- 名前
TSCORE
- コメント
指定データ全体を母集団としたときの各値の偏差値を求めます
- 参照範囲
=LAMBDA(データ列,
LET(
vals, CHOOSECOLS(データ列, 1),
μ, AVERAGE(vals),
σ, STDEV.P(vals),
IF(ISNUMBER(vals),
((vals - μ)*10)/σ + 50,
vals & ""
)
)
)
【構文】
TSCORE(データ列)
【引数】
| 引数 | 内容 |
|---|---|
| データ列 | 1列からなるデータのセル範囲または配列 |
【戻り値】
データ列内における各データの偏差値
【説明】
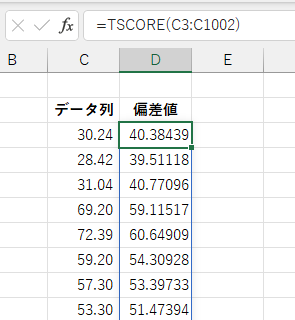
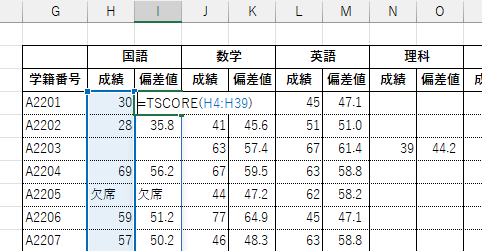
TSCORE 関数は指定したデータ列の値の分布から各値の偏差値を求め、配列として返します。結果は縦方向にスピルします。
入力データとしては指定されたセル範囲または配列の1列目の値のみを対象とします。 複数列からなるデータが与えられたても、2列目以降は無視されます。
データ範囲に空欄(空白セル)があった場合、偏差値の統計計算からは除外され、結果も空欄(空文字列)となります。
データに文字列や論理値など数値以外の値があった場合も同様に計算上から除外され、結果はその値がコピーされます。
【使用例】
度数分布
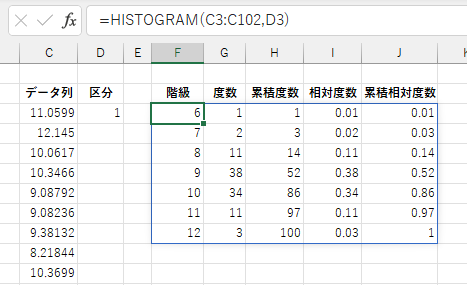
【名前の定義】
- 名前
HISTOGRAM
- コメント
指定データの値から階級別の度数の分布を求めます
- 参照範囲
=LAMBDA([データ列], [区分],
LET(
_is_array, LAMBDA(a, TYPE(a)=64),
_visible_rows, LAMBDA(a,
IF(ISREF(a),
FILTER(a, BYROW(a, LAMBDA(r, AGGREGATE(3,3,r)>0))),
a
)
),
gen_bins, LAMBDA(from, to, step, LET(
min, FLOOR(from, step),
max, FLOOR(to, step),
cnt, (max-min)/step + 1,
SEQUENCE(cnt,, min, step)
)),
IF(ISOMITTED(データ列),
{"階級", "度数", "累積度数", "相対度数", "累積相対度数"},
LET(
vals, SORT(TOCOL(_visible_rows(データ列))),
divs, IF(ISOMITTED(区分), "", 区分),
bins, IF(_is_array(divs),
SORT(UNIQUE(TOCOL(divs))),
IF(ISNUMBER(divs),
gen_bins(MIN(vals), MAX(vals), divs),
SORT(UNIQUE(vals))
)
),
clsx, XMATCH(vals, bins, -1, 2),
cls, FILTER(clsx, NOT(ISERROR(clsx))),
freq, MAP(SEQUENCE(ROWS(bins)), LAMBDA(bin, COUNT(FILTER(cls, cls=bin)))),
cumfreq, SCAN(0, freq, LAMBDA(cum, f, cum+f)),
relfreq, freq/SUM(freq),
cumrelfreq, cumfreq/SUM(freq),
HSTACK(
bins,
freq,
cumfreq,
relfreq,
cumrelfreq
)
)
)
)
)
【構文】
HISTOGRAM([データ列], [区分])
【引数】
| 引数 | 内容 |
|---|---|
| データ列 | 偏差値を求めるデータ列のセル範囲または配列 |
| 区分 | 階級を与える区分間隔か下限境界値の配列 |
【戻り値】
各階級における以下の度数量
- 度数
- 累積度数
- 相対度数
- 累積相対度数
【説明】
HISTOGRAM 関数はヒストグラムの作成に使える階級別の各種度数分布を出力します。
「データ列」には度数分布を求めたいデータをセル範囲か配列として指定します。 集計されるデータは1列目のみで、2列目以降は無視されます。
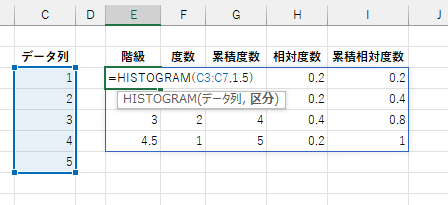
「データ列」を省略すると各統計量の名前を横方方向の配列として返します。 これは集計結果の見出しとして使います。
「区分」には数値か数値配列を指定します。また省略することもできます。
「区分」に1個の数値を指定した場合、その間隔によって区切られた区間の度数を集計します。各区間の境界は下限以上、上限未満です。 区分の数はデータ列の最小値と最大値から
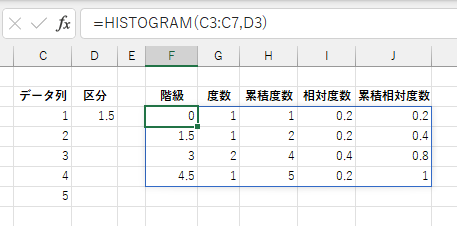
「区分」に複数の数値からなるセル範囲か配列を指定した場合、それら境界値とする各区間の度数を集計します。各区間の境界は下限以上、上限未満です。 最小区分値未満の値は除外されます。最大区分には最大区分値以上の値が全て含まれます。
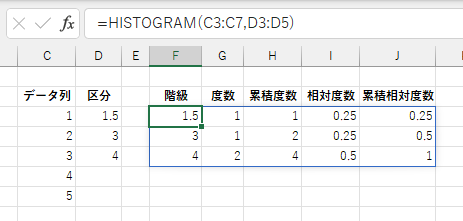
「区分」を省略した場合、データ列内の同一値よる度数分布を集計します。 数値だけでなく、文字列によるカテゴリ別度数集計もできます。ただし、英字の大文字と小文字は区別しません。
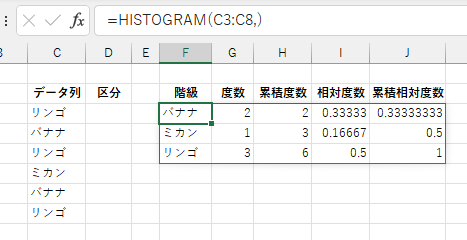
HISTOGRAM 関数では、非表示となっているデータ行を計算から除外するようになっています。
たとえばテーブルの一部のデータのみを集計対象としたいときには、フィルターやグループ化で絞り込めれば、表示範囲に限定した度数分布が求まります。
【使用例】
区分の境界値を配列で指定します。
=HISTOGRAM(A2:A1001, {400,600,1000,1500})
注文テーブルから列(商品コード)を列名(構造化参照)で指定します。 文字列による集計なので2番目の引数(区分)を省略します。
=HISTOGRAM(販売実績[商品コード])
アクセルログから、10分毎のアクセス回数を調べます。
=HISTOGRAM(アクセスログ[timestamp], "0:10:00")
販売実績テーブルから2022年の月次の販売件数を集計します。
=HISTOGRAM(販売実績[日付], DATE(2022, SEQUENCE(12),1))
ABC分析
【名前の定義】
- 名前
ABC
- コメント
データ列から各値のABC判定をします。
- 参照範囲
=LAMBDA([データ列], [Aランク比], [Bランク比],
IF(ISOMITTED(データ列),
{"累積構成比", "ABCランク"},
LET(
data, CHOOSECOLS(データ列, 1),
A, IF(ISOMITTED(Aランク比), 0.7, Aランク比 * 1),
B, IF(ISOMITTED(Bランク比), 0.9, Bランク比 * 1),
IFS(
OR(ISERROR(A), ISERROR(B)), #VALUE!,
OR(A < 0.0, B > 1.0, A >= B), #VALUE!,
TRUE, LET(
total, SUM(data),
ccr, SCAN(0, SORT(data,1,-1), LAMBDA(a, b, a + b)) / total,
abc, MAP(ccr, LAMBDA(r,
IFS(
r <= A, "A",
r <= B, "B",
TRUE, "C"
)
)),
result, HSTACK(ccr, abc),
SORTBY(result, SORTBY(SEQUENCE(ROWS(data)), data, -1))
)
)
)
)
)
【構文】
ABC([データ列], [Aランク比], [Bランク比])
【引数】
| 引数 | 内容 |
|---|---|
| データ列 | ABC判定をするデータ列のセル範囲または配列 |
| Aランク比 | Aランク判定される累積構成比 |
| Bランク比 | Bランク判定される累積構成比 |
【戻り値】
指定データの各項について以下の値をもつ配列
- 累積構成比
- ABC ランク
【説明】
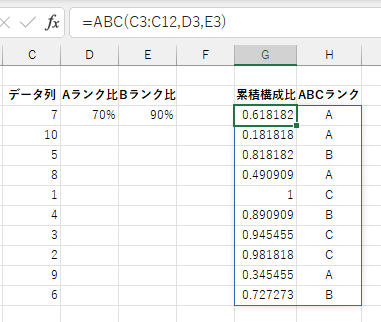
ABC 関数は指定のデータをABC分析します。 各項の累積構成比から A、B、C のいずれかのランク(クラス)分けを文字で表します。
結果は各項の累積構成比と ABC 判定結果を2列の配列としてスピルします。
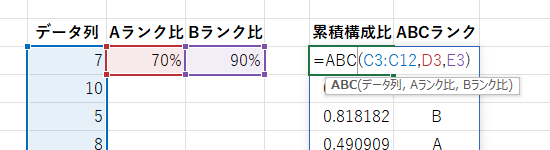
「データ列」には ABC 分析をしたいデータをセル範囲か配列として指定します。 判定対象はデータは1列目のみで、2列目以降は無視されます。
「データ列」が省略されて他場合、統計量の列の名称が横方向の配列として出力されます。 これは列の見出しにも使用できます。
「A ランク比」、「B ランク比」には、A 判定、B 判定される累積構成比を 0 から 1 までの小数値で指定します。 累積構成比を百分率(%)で表したい場合には文字列として指定できます。
=ABC(A2:A101, 0.7, 0.9) =ABC(A2:A101, "70%", "90%")
各項の累積構成比によって
- 「Aランク比」以下なら A 判定
- 「Aランク比」を超えて「B ランク比」以下なら B 判定
- 「Bランク比」を超えてたなら C 判定
となります。
「Aランク比」は「Bランク比」より小さな値でなければなりません。そうでなければエラーとなります。
「Aランク比」、「Bランク比」は省略できます。
=ABC(A2:A101,,)
その場合デフォルトで
- Aランク比 = 0.7 (70%)
- Bランク比 = 0.9 (90%)
となります。
個数データのように分布が荒く、同じ値が多数含まれるようなデータでは注意が必要です。 同じ値を持つ項の累積構成比がたまたまクラス境界を跨ぐような並びになった場合、それらはその時の位置によって上位と下位の異なるクラスへへ別々に仕分けられます。
【使用例】
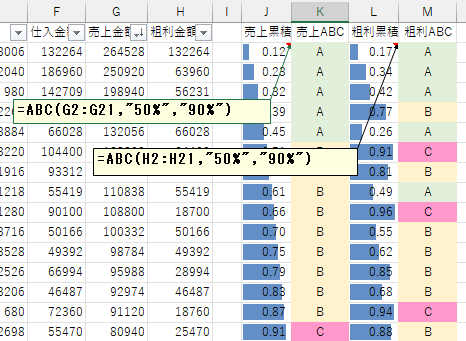
ABC 関数では元データをあらかじめソートした表を用意しておく必要がありません。
そのため、クロス ABC 分析のように、複数系列のデータについての同時に ABC 判定したい場合でも、一つの表からそのまま横並びで結果を出力することができます。
【関連記事】
バスケット分析
【名前の定義】
- 名前
BASKET
- コメント
伝票にある品目の組み合わせについてマーケットバスケット分析値を算出します
- 参照範囲
=LAMBDA([伝票列], [品目列],
LET(
_combine, LAMBDA(a,b,LET(
ac,ROWS(a),
bc,ROWS(b),
aa, CHOOSECOLS(a,SEQUENCE(bc,1,1,0)),
bb, CHOOSECOLS(b,SEQUENCE(ac,1,1,0)),
HSTACK(
TOCOL(aa),
TOCOL(TRANSPOSE(bb))
)
)),
_frequency, LAMBDA(a, LET(
vals, SORT(CHOOSECOLS(a, 1)),
uniq_vals, UNIQUE(vals),
seq, SEQUENCE(ROWS(uniq_vals)),
pos_1, XMATCH(uniq_vals, vals, 0, 2),
pos_2, IF(seq < ROWS(seq), INDEX(pos_1, seq + 1, 1), ROWS(vals)+1),
freqs, pos_2 - pos_1,
HSTACK(uniq_vals, freqs)
)),
IF(ISOMITTED(伝票列),
{"品目1", "品目2", "支持度", "信頼度", "リフト"},
//{"品目1", "品目2", "度数1", "度数2", "共起度数", "支持度", "信頼度", "期待信頼度", "リフト"},
LET(
basket_items, UNIQUE(HSTACK(CHOOSECOLS(伝票列, 1), CHOOSECOLS(品目列, 1)), FALSE),
baskets, CHOOSECOLS(basket_items, 1),
items, CHOOSECOLS(basket_items, 2),
basket_count, ROWS(UNIQUE(baskets)),
item_count, ROWS(UNIQUE(items)),
item_freqs, _frequency(CHOOSECOLS(basket_items, 2)),
item_pair_set, _combine(CHOOSECOLS(item_freqs, 1), CHOOSECOLS(item_freqs, 1)),
cooccurences, MAP(
CHOOSECOLS(item_pair_set, 1),
CHOOSECOLS(item_pair_set, 2),
LAMBDA(l, r, LET(
bks, FILTER(baskets, (items=l)+(items=r)),
ROWS(bks) - ROWS(UNIQUE(bks))
))
),
lhs_freqs, MAP(
SEQUENCE(ROWS(item_pair_set)),
LAMBDA(i,
INDEX(item_freqs, INT((i-1)/item_count) + 1, 2)
)
),
rhs_freqs, SORTBY(lhs_freqs, CHOOSECOLS(item_pair_set, 2)),
supports, cooccurences / basket_count,
confidences, cooccurences / lhs_freqs,
expected_confidences, rhs_freqs / basket_count,
lifts, confidences / expected_confidences,
FILTER(
HSTACK(
item_pair_set,
//lhs_freqs,
//rhs_freqs,
//cooccurences,
supports,
confidences,
//expected_confidences,
lifts
),
cooccurences > 0
)
)
)
)
)
【構文】
BASKET(伝票列, 品目列)
【引数】
| 引数 | 内容 |
|---|---|
| 伝票列 | 同一会計を識別するIDのセル範囲または配列 |
| 品目列 | 組み合わせ対象のセル範囲または配列 |
【戻り値】
各品目の組み合わせに対する、以下の統計量
- 度数
- 比率
- 支持度
- 信頼度
- リフト値
【説明】
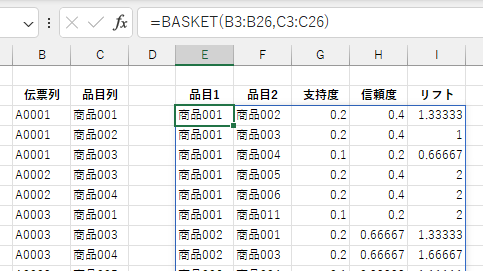
BASKET 関数は会計データから品目のマーケットバスケット分析(アソシエーション分析)の各種統計量を算出します。
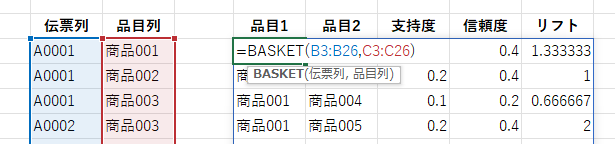
「伝票列」にはバスケットとなる会計を識別するID(レシート番号や顧客IDなど)を指定します。 分析対象となるデータは1列目のみで、2列目以降は無視されます。
「伝票列」を省略すると各統計量の名前を横方向の配列として返します。 これはバスケット分析結果の見出しとして使います。
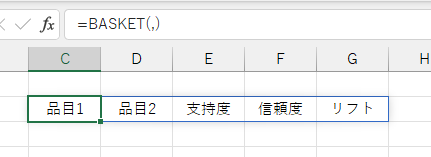
「品目列」には組み合わせ対象となる品目(商品名や商品コードなど)の列を指定します。 分析対象となるデータは1列目のみで、2列目以降は無視されます。
「品目列」の文字列の大文字と小文字は区別されません。
【注意】
この関数はとても重いです。データ量(特に品目種)が多いと結果が出るまでに非常に時間がかかるだけでなく、Excel 全体が重くなって Excel 操作さえままならなくなります。
大量の実データを扱うような本格的な分析にはちょっと実用的でないので注意してください。
【使用例】
POS データから商品のバスケット分析をします。
=BASKET(POS履歴[レシート番号], POS履歴[商品名])
AFE ソース
Excel に Advanced Formula Environment アドインを導入されている上級者のために、本記事掲載の全てのユーザー定義関数を一括登録できるソースを用意しました。
以下のソースを AFE の Editor にコピー&ペーストしてください。 関数名の衝突を避けるため、任意の名前で専用の Namespace を用意することをお勧めします。
// シーゴのExcel研究室
// 【Excel LAMBDA】データ分析編【ユーザー定義関数集】
// https://www.shegolab.jp/entry/excel-lambda-data-analysis-01
// 変更履歴
// [2022/07/18] 公開
// [2022/10/20] 省略可引数をオプショナルに修正
// [2022/11/03] 一部処理を新配列関数で差し替え
/**
* 基本統計量
*/
SUMMARY
=LAMBDA([データ列], [カテゴリ列],
LET(
_visible_rows, LAMBDA(a,
IF(ISREF(a),
FILTER(a, BYROW(a, LAMBDA(r, AGGREGATE(3,3,r)>0))),
a
)
),
LET(
measureNames, {
"個数",
"合計",
"平均",
"中央値",
"最頻値",
"最小値",
"最大値",
"分散",
"標準偏差",
"尖度",
"歪度"
},
measureFuncs, LAMBDA(i, a,
CHOOSE(i,
COUNT(a),
SUM(a),
AVERAGE(a),
MEDIAN(a),
MODE.SNGL(a),
MIN(a),
MAX(a),
VAR.P(a),
STDEV.P(a),
KURT(a),
SKEW(a)
)
),
IF(ISOMITTED(データ列),
IF(ISOMITTED(カテゴリ列),
measureNames,
UNIQUE(_visible_rows(カテゴリ列))
),
IF(ISOMITTED(カテゴリ列),
LET(
vals, _visible_rows(データ列),
MAKEARRAY(1, COLUMNS(measureNames),
LAMBDA(r, c, measureFuncs(c, vals))
)
),
LET(
vals, _visible_rows(データ列),
categories, _visible_rows(カテゴリ列),
groups, UNIQUE(categories),
gids, XMATCH(categories, groups, 0, 1),
MAKEARRAY(ROWS(groups), COLUMNS(measureNames),
LAMBDA(gid, m, measureFuncs(m, FILTER(vals, gid=gids))))
)
)
)
)
)
)
;
/**
* 偏差値
*/
TSCORE
=LAMBDA(データ列,
LET(
vals, CHOOSECOLS(データ列, 1),
μ, AVERAGE(vals),
σ, STDEV.P(vals),
IF(ISNUMBER(vals),
((vals - μ)*10)/σ + 50,
vals & ""
)
)
)
;
// - AVERAGE や STDEV.P は、数値以外の要素を除外して計算する
// - 数値以外で空文字列を連結するのは、空白セルの結果を 0 にさせないため
/**
* 度数分布
*/
HISTOGRAM
=LAMBDA([データ列], [区分],
LET(
_is_array, LAMBDA(a, TYPE(a)=64),
_visible_rows, LAMBDA(a,
IF(ISREF(a),
FILTER(a, BYROW(a, LAMBDA(r, AGGREGATE(3,3,r)>0))),
a
)
),
gen_bins, LAMBDA(from, to, step, LET(
min, FLOOR(from, step),
max, FLOOR(to, step),
cnt, (max-min)/step + 1,
SEQUENCE(cnt,, min, step)
)),
IF(ISOMITTED(データ列),
{"階級", "度数", "累積度数", "相対度数", "累積相対度数"},
LET(
vals, SORT(TOCOL(_visible_rows(データ列))),
divs, IF(ISOMITTED(区分), "", 区分),
bins, IF(_is_array(divs),
SORT(UNIQUE(TOCOL(divs))),
IF(ISNUMBER(divs),
gen_bins(MIN(vals), MAX(vals), divs),
SORT(UNIQUE(vals))
)
),
clsx, XMATCH(vals, bins, -1, 2),
cls, FILTER(clsx, NOT(ISERROR(clsx))),
freq, MAP(SEQUENCE(ROWS(bins)), LAMBDA(bin, COUNT(FILTER(cls, cls=bin)))),
cumfreq, SCAN(0, freq, LAMBDA(cum, f, cum+f)),
relfreq, freq/SUM(freq),
cumrelfreq, cumfreq/SUM(freq),
HSTACK(
bins,
freq,
cumfreq,
relfreq,
cumrelfreq
)
)
)
)
)
;
/**
* ABC分析
*/
ABC
=LAMBDA([データ列], [Aランク比], [Bランク比],
IF(ISOMITTED(データ列),
{"累積構成比", "ABCランク"},
LET(
data, CHOOSECOLS(データ列, 1),
A, IF(ISOMITTED(Aランク比), 0.7, Aランク比 * 1),
B, IF(ISOMITTED(Bランク比), 0.9, Bランク比 * 1),
IFS(
OR(ISERROR(A), ISERROR(B)), #VALUE!,
OR(A < 0.0, B > 1.0, A >= B), #VALUE!,
TRUE, LET(
total, SUM(data),
ccr, SCAN(0, SORT(data,1,-1), LAMBDA(a, b, a + b)) / total,
abc, MAP(ccr, LAMBDA(r,
IFS(
r <= A, "A",
r <= B, "B",
TRUE, "C"
)
)),
result, HSTACK(ccr, abc),
SORTBY(result, SORTBY(SEQUENCE(ROWS(data)), data, -1))
)
)
)
)
)
;
// - 累積構成比の出力はいらなかったかも
// - ABC固定ではなく、ランク数が可変のようなクラス分けの場合、MAP/IFS より XLOOKUP が使える
/**
* バスケット分析
*/
BASKET
=LAMBDA([伝票列], [品目列],
LET(
_combine, LAMBDA(a,b,LET(
ac,ROWS(a),
bc,ROWS(b),
aa, CHOOSECOLS(a,SEQUENCE(bc,1,1,0)),
bb, CHOOSECOLS(b,SEQUENCE(ac,1,1,0)),
HSTACK(
TOCOL(aa),
TOCOL(TRANSPOSE(bb))
)
)),
_frequency, LAMBDA(a, LET(
vals, SORT(CHOOSECOLS(a, 1)),
uniq_vals, UNIQUE(vals),
seq, SEQUENCE(ROWS(uniq_vals)),
pos_1, XMATCH(uniq_vals, vals, 0, 2),
pos_2, IF(seq < ROWS(seq), INDEX(pos_1, seq + 1, 1), ROWS(vals)+1),
freqs, pos_2 - pos_1,
HSTACK(uniq_vals, freqs)
)),
IF(ISOMITTED(伝票列),
{"品目1", "品目2", "支持度", "信頼度", "リフト"},
//{"品目1", "品目2", "度数1", "度数2", "共起度数", "支持度", "信頼度", "期待信頼度", "リフト"},
LET(
basket_items, UNIQUE(HSTACK(CHOOSECOLS(伝票列, 1), CHOOSECOLS(品目列, 1)), FALSE),
baskets, CHOOSECOLS(basket_items, 1),
items, CHOOSECOLS(basket_items, 2),
basket_count, ROWS(UNIQUE(baskets)),
item_count, ROWS(UNIQUE(items)),
item_freqs, _frequency(CHOOSECOLS(basket_items, 2)),
item_pair_set, _combine(CHOOSECOLS(item_freqs, 1), CHOOSECOLS(item_freqs, 1)),
cooccurences, MAP(
CHOOSECOLS(item_pair_set, 1),
CHOOSECOLS(item_pair_set, 2),
LAMBDA(l, r, LET(
bks, FILTER(baskets, (items=l)+(items=r)),
ROWS(bks) - ROWS(UNIQUE(bks))
))
),
lhs_freqs, MAP(
SEQUENCE(ROWS(item_pair_set)),
LAMBDA(i,
INDEX(item_freqs, INT((i-1)/item_count) + 1, 2)
)
),
rhs_freqs, SORTBY(lhs_freqs, CHOOSECOLS(item_pair_set, 2)),
supports, cooccurences / basket_count,
confidences, cooccurences / lhs_freqs,
expected_confidences, rhs_freqs / basket_count,
lifts, confidences / expected_confidences,
FILTER(
HSTACK(
item_pair_set,
//lhs_freqs,
//rhs_freqs,
//cooccurences,
supports,
confidences,
//expected_confidences,
lifts
),
cooccurences > 0
)
)
)
)
)
;
// - 重い、重すぎる
// - 品目にして100種類程度が限界か
// - 重いのは FILTER を掛ける処理
// - 品目の組み合わせの数だけ FILTER を回している
// - それでも 伝票×品目のマトリックスを作成して集計するよりかはマシだった
// - 伝票、品目が文字列の場合、比較が重い。
// - 伝票、品目に整数でIDをふり、比較突き合わせをすれば、多少のパフォーマンスが向上が見込める
// - プログラムが長くなるのでパス
// - XMATCHは検索モードを完全一致にしても大小文字を区別しない
// - UNIQUE も同様
// EOF
変更履歴
- [2022-07-18] 公開
- [2022-10-20] 関数の省略できる引数をオプショナルに修正